



DATA SCIENCE ACCURACY
Can an algorithm predict hit songs?
Let’s explore how we can successfully build a hit song classifier using only audio features, as described in my publication (Herremans et al., 2014).
During my PhD research I came across a paper by Pachet & Roi (2008) entitled “Hit song science not yet a science”. This was intriguing to me, and caused me to explore if we could in fact predict hit songs. Research on this topic is very limited, for a more complete literature overview, please see Herremans et al. (2014). We decided that the effectiveness of the model could be optimized by focusing on one specific genre: dance music. This makes intuitive sense to me, as different genres of music, would have different characteristics for becoming a hit song.

// Dataset
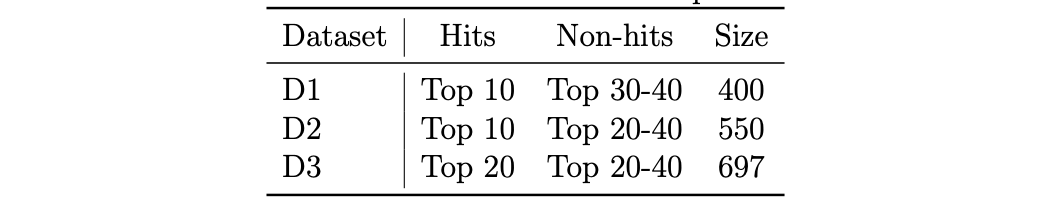
In order to be able to do hit prediction, we first need a dataset of hit / non-hit songs. While there is no shortage of hit-lists, it is quite another thing to find non-hit lists. Therefore, we decided to classify between high and low ranked songs on the hit listings. We experimented a bit to see which split would work best, as shown in Table 1, this resulted in three datasets (D1, D2, and D3):

Each with slightly unbalanced class distribution:
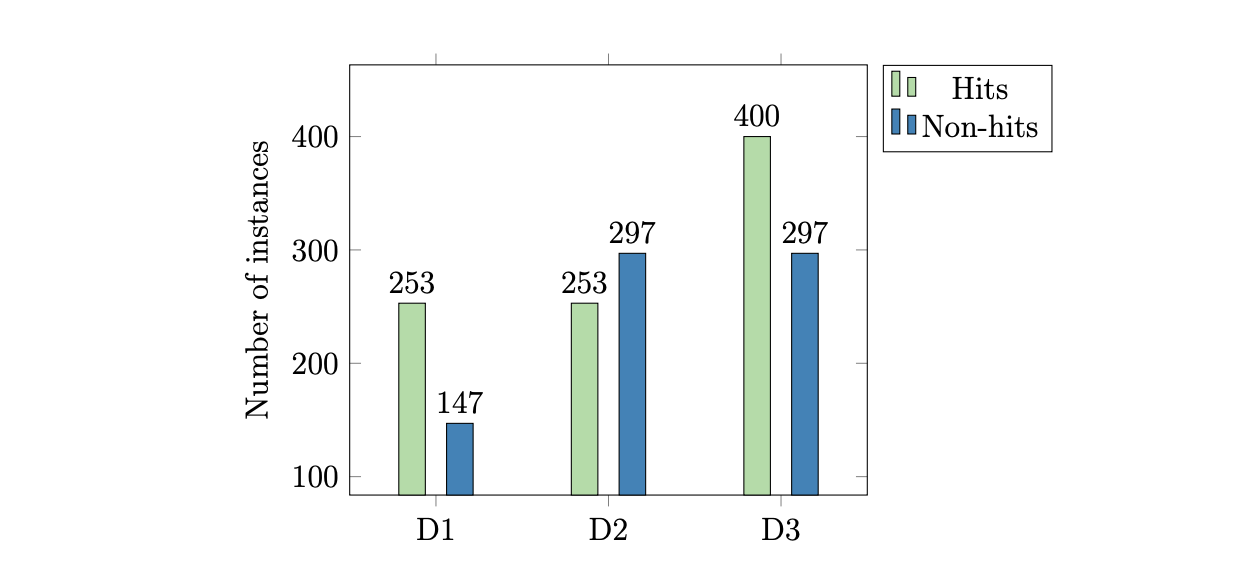
The hit listings were collected from two sources: Billboard (BB) and the Original Charts Company (OCC). The table below shows the amount of hits collected. Note that songs stay in the charts for multiple weeks, so the amount of unique songs is much smaller:
Now that we have a list of songs, we need the audio features that go along with them. We used The Echo Nest Analyzer (Jehan and DesRoches, 2012), to extract a number of audio features. This nifty API allows us to get a number of audio features, based only on the artist name and song title. The Echo Nest was bought by Spotify and is now integrated in Spotify API. So what did we extract:
1. Standard audio features:
These included Duration, Tempo, Time signature, Mode (major (1) or minor (0)), Key, Loudness, Danceability (Calculated by The Echo Nest, based on beat strength, tempo stability, overall tempo, and more), Energy (Calculated by The Echo Nest, based on loudness and segment durations).
2. New temporal features
Because songs change over time, we added a number of temporally aggregated features based on Schindler & Rauber (2012). They include average, variance, min, max, range, and 80 percentile of ~1s segments. This was done for the following features:
Timbre — PCA basis vector (13 dimensions) of the tone colour of the audio. A 13-dimensional vector which captures the tone colour for each segment of a song.
Beat diff erence— The time between beats.
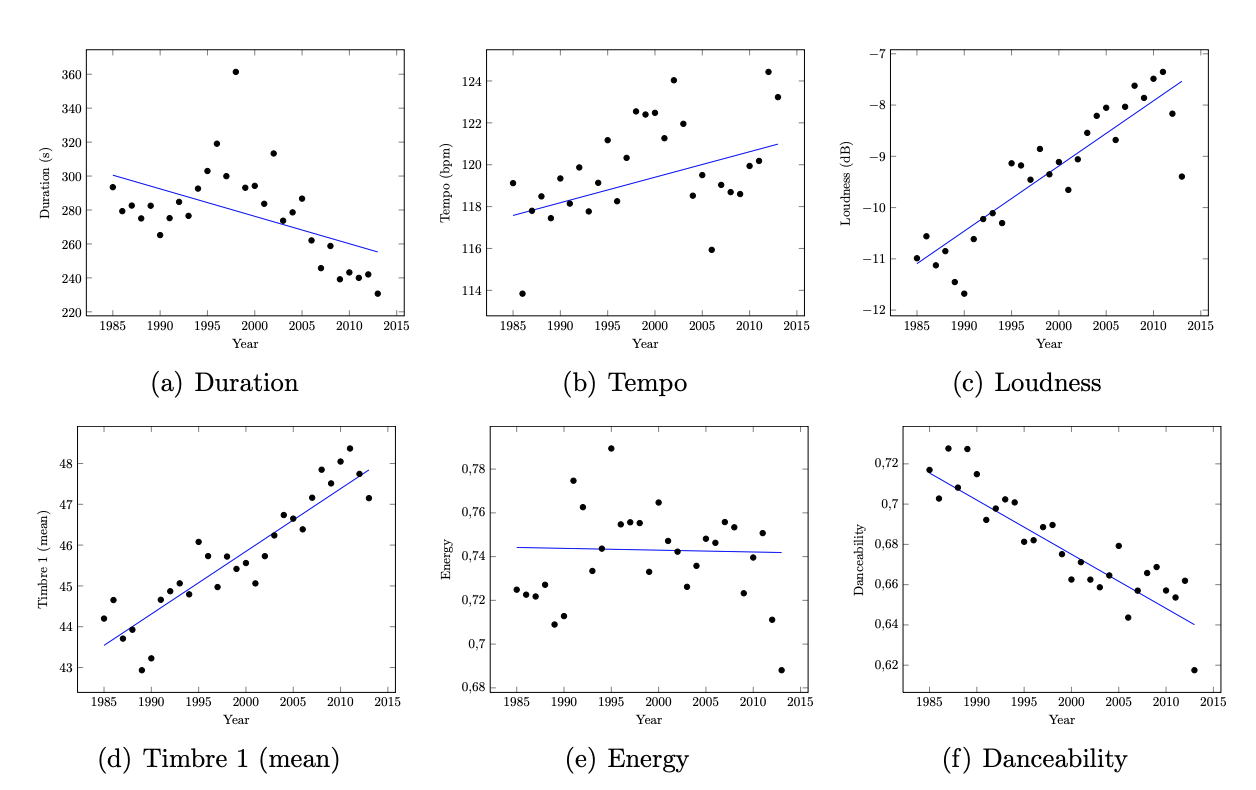
Great! Now we have a nice collection of audio features, together with their top chart position. Like any good data science project should start, let’s do some data visualisation. The first thing we notice is that hits change over time. What was a hit ten years ago, is not necessarily a hit song today. When we visualise our features over time, this becomes apparent:
Interestingly, we see that dance hit songs have become shorter, louder, and according to the Echo Nest ‘danceability’ features, less danceable!
For a more complete visualisation of features over time, check out my short paper on visualising hit songs: (Herremans & Lauwers, 2017) and accompanying webpage.
// Models
Two types of models are explored: comprehensible ones and black-boxmodels. As can be expected, the latter are more efficient, but the former give us insight into why a song can be considered a hit.
Decision tree (C4.5)
In order to fit the decision tree on a page, I’ve set the pruning to high. This makes the tree small and comprehensible, but gives is a low AUC of 0.54 on D1. We see that only temporal features are present! This mean they must be important. In particular Timbre 3 (third dimension of PCA timbre vector), which reflects the emphasis of the attack (sharpness), seems influential in order to predict hit songs.
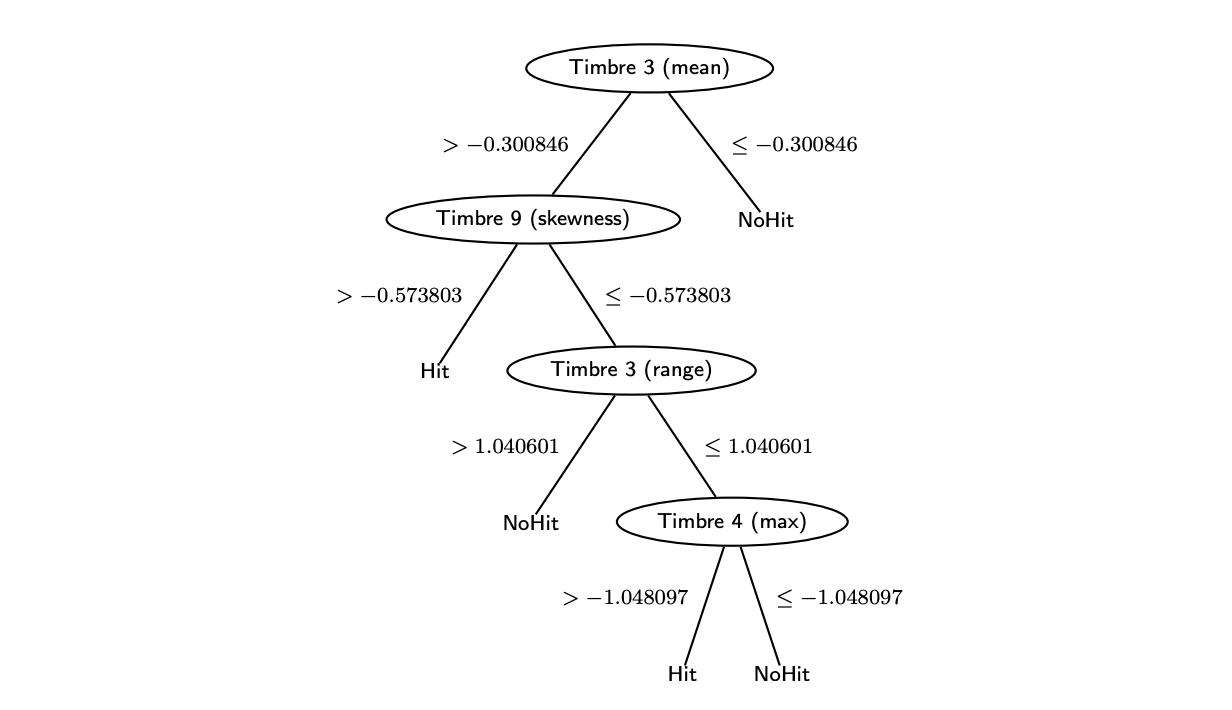
Rule based model (Ripper)
Using RIPPER, we get a very similar ruleset to the decision tree. Again Timbre 3 is present. This time, our AUC is 0.54 on D1.

Naive Bayes, Logistic regression, Support vector machines (SVM)
For an easy to read description of these techniques, please refer to Herremans et al. (2014).
// Final results
Before going into any results, I should stress that it makes no sense to use a general classification ‘accuracy’ here, because the classes are not balanced (see Figure 1). If you want to use accuracy, it should be class specific. This is a common mistake, but very important to keep in mind. We therefore use Receiver Operator Curve (ROC), Area Under The Curve (AUC) and Confusion Matrices to properly evaluate the models.
10-fold cross validation
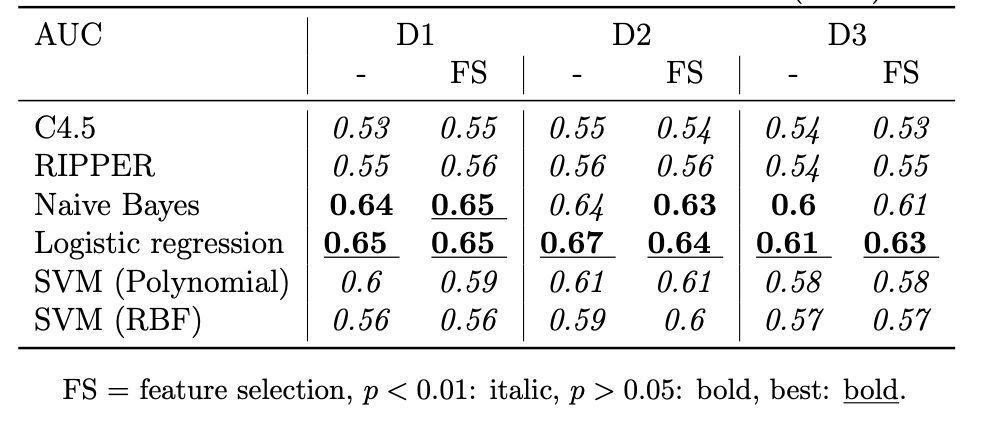
We obtain the best results for Dataset 1 (D1) and Dataset 2 (D2), without feature selection (we used CfsSubsetEval with Genetic Search). All features were standardized before training. Since D3 has the smallest ‘split’ between hits and non-hits this result makes sense. Overall, logistic regression performs best.
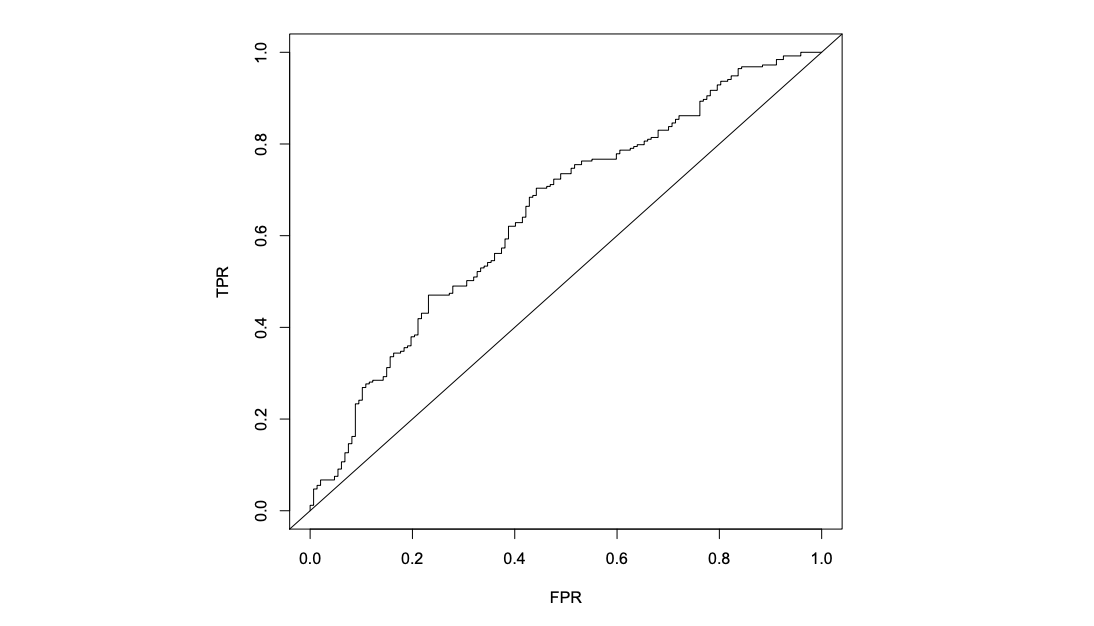
Looking at the ROC curve below, we see that the model outperforms a random oracle (diagonal line).

Details of the classification accuracy can be seen by looking at the confusion matrix, which reveals that correctly identifying non-hit songs is not easy! Hits, however, are identified correctly 68% of the time.

Out of time test set
Instead of 10-fold cross validation, we also used a test set of chronologically ‘new’ songs. This resulted in a further performance increase:
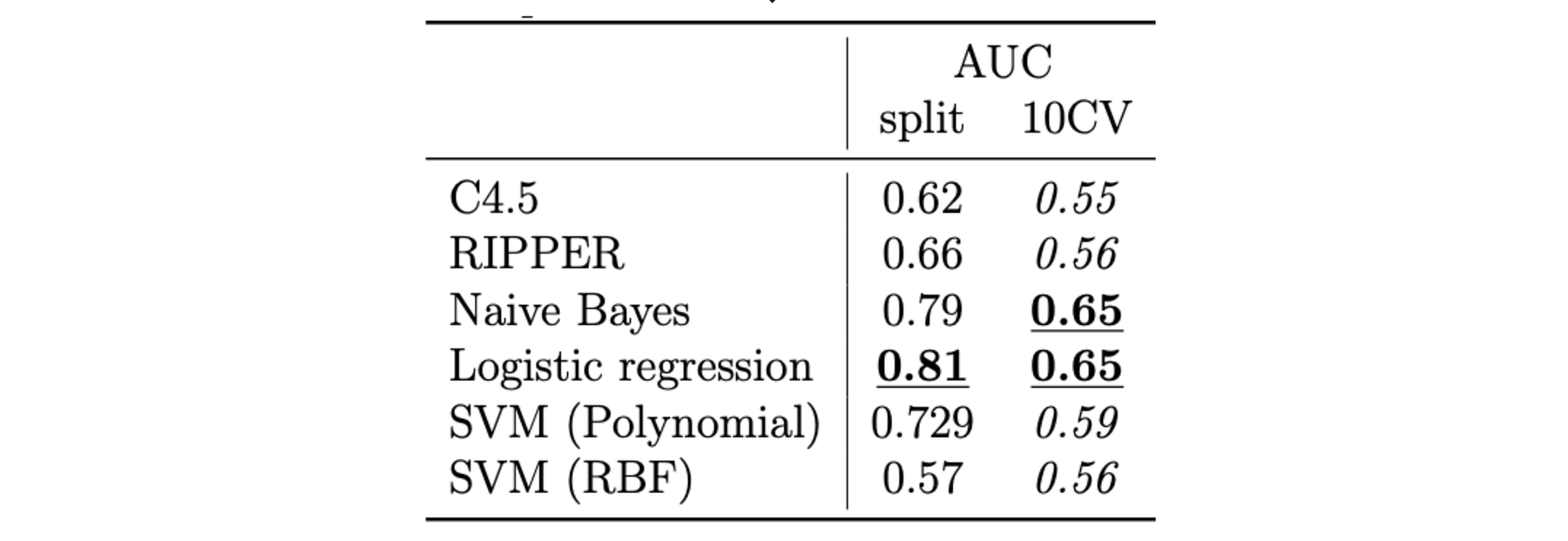
It’s intriguing that the model predicts better for newer songs. What causes this skewness? Maybe it learns to predict how trends evolve over time? Future research should look into the intriguing evolution of music preferences over time.
// Conclusion
Looking solely at audio features, Herremans et al. (2014) could predict with an AUC of 81% if a song would be in the top 10 hit listings. Can we do even better? Most probably yes! The features set we looked at in this research is limited, so by expanding this using both low and high level musical features, higher accuracies may be achieved. In addition, in follow up research, I looked at the influence of social networks on hit prediction, which also has a significant impact (Herremans & Bergmans, 2017).
[+] Prof. Dr. Dorien Herremans — dorienherremans.com
References
Herremans, D., Martens, D., & Sörensen, K. (2014). Dance hit song prediction. Journal of New Music Research, 43(3), 291–302. [preprint link]
Herremans, D., & Bergmans, T. (2017). Hit song prediction based on early adopter data and audio features. The 18th International Society for Music Information Retrieval Conference (ISMIR) — Late Breaking Demo. Shuzou, China [preprint link]
Herremans D., Lauwers W.. 2017. Visualizing the evolution of alternative hit charts. The 18th International Society for Music Information Retrieval Conference (ISMIR) — Late Breaking Demo. Shuzou, China [preprint link]
Pachet, F., & Roy, P. (2008, September). Hit Song Science Is Not Yet a Science. In ISMIR (pp. 355–360).
Schindler, A., & Rauber, A. (2012, October). Capturing the temporal domain in echonest features for improved classification effectiveness. In International Workshop on Adaptive Multimedia Retrieval (pp. 214–227). Springer, Cham.






